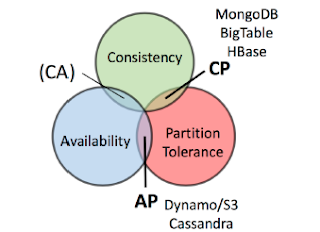
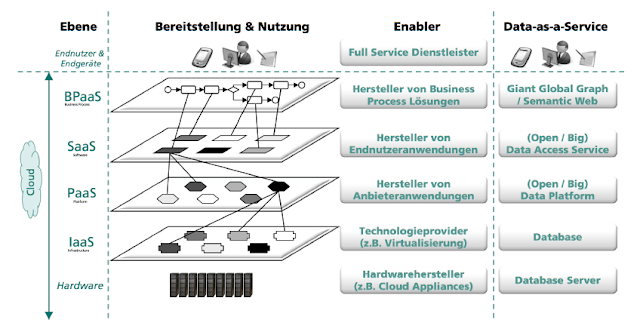
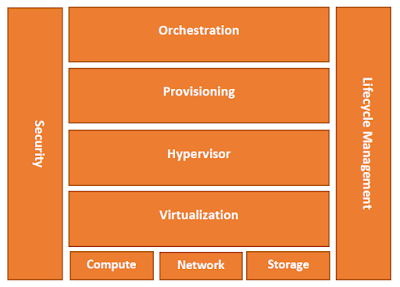
Projektverlauf Praktikas

Praktikum 1 Das erste Praktikum war der Start in das BPaaS Projekt. Dort ist zum ersten Mal das Projektteam zusammengekommen. Recht schnell hat sich herausgestellt, dass die Teammitglieder aus der technischen Informatik in unserem Team überwiegen. Dies ist im Hinblick auf die Verwirklichung des Projektes bestimmt ein Vorteil, jedoch bedeutet dies dann auch eine starke Orientierung auf die technischen Themen. Recht schnell ging es dann zur Diskussion über die Projektaufgabe "Entwicklung einer BPaaS-Plattform". Als Vorbereitung auf das Praktikum hatten wir uns das Aufgabenblatt von Frau Steffens durchgelesen und haben überlegt welche Komponenten wir brauchen, um alle User mit der Plattform zufriedenzustellen. Edgar hatte sich zu den Komponenten schon im Vorfeld Gedanken gemacht und dieses zur Diskussion im Praktikum vorgestellt (siehe diesen Blogeintrag ). Letztendlich waren seine Ideen schon sehr gut und wir sind auf eine ähnliche Architektur im Praktikum gekommen. ...